本篇的主要内容为本人在2019年华为人工智能校园创新大赛比赛中的经验总结,在比赛中参与的作品为“沙漏计事”,是一款记事型app。在其中,我负责的部分是应用的ai模块的嵌入。以华为提供的HiAI为媒介,我将语音识别、自然语言处理接口嵌入到应用中,同时,我还利用他们提供的模型转换功能,将一个自训练的文本分类模型封装并嵌入到应用中。
0 概述
以2019年华为人工智能校园创新大赛为契机,“沙漏记事”得以在多年的尘封中得到再次发展。“沙漏记事”是我们队长kofes本科以来就想要完成的作品。在这样一个难得的条件下,我们队伍四人决定一起完成这份一直未能实现的设计。
1 项目介绍
沙漏记事 (以下简称应用) 是一款提供用户制定计划并实现计时提醒服务的手机应用。有别于同类型的竞品应用,在华为HIAI技术的支持下 (离线语音识别、自然语义理解等),它呈现了一种一呼直达、知悉意图的智能交互方案。最直白的效果就是,你通俗地描述一句待办,不用复杂繁琐的设置操作,应用一步到位即可帮你设定好主题、期限或者周期的提醒安排。与此同时,我们还充分挖掘了应用的应用价值,在基础功能的前提下融入了多套可视化管理和分析工具,为你提供更加专业的记事、计划、提醒的管理方式,旨在帮助你养成受益终身的时间管理习惯。
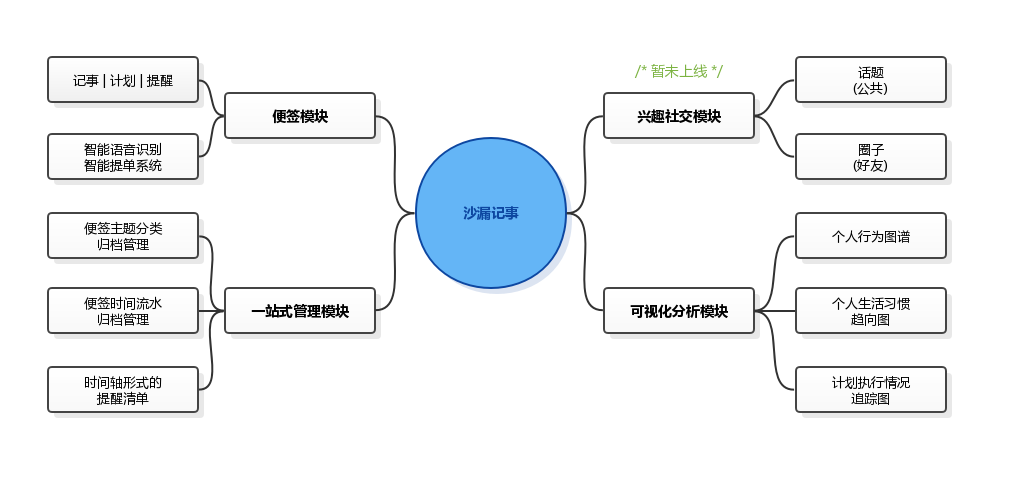
如图 1-1 所示,应用由四大模块构成,分别是便签模块、一站式管理模块、可视化分析模块以及兴趣社交模块 (社交模块暂未上线)。便签记事、计划提醒作为应用的主线功能,而一站式管理模块、可视化分析模块以及兴趣社交模块始终服务于主线功能。这正是创造这款应用的初衷,既管再丰富的功能拓展也是为了做好一件事,旨在帮助用户养成良好的时间管理习惯。
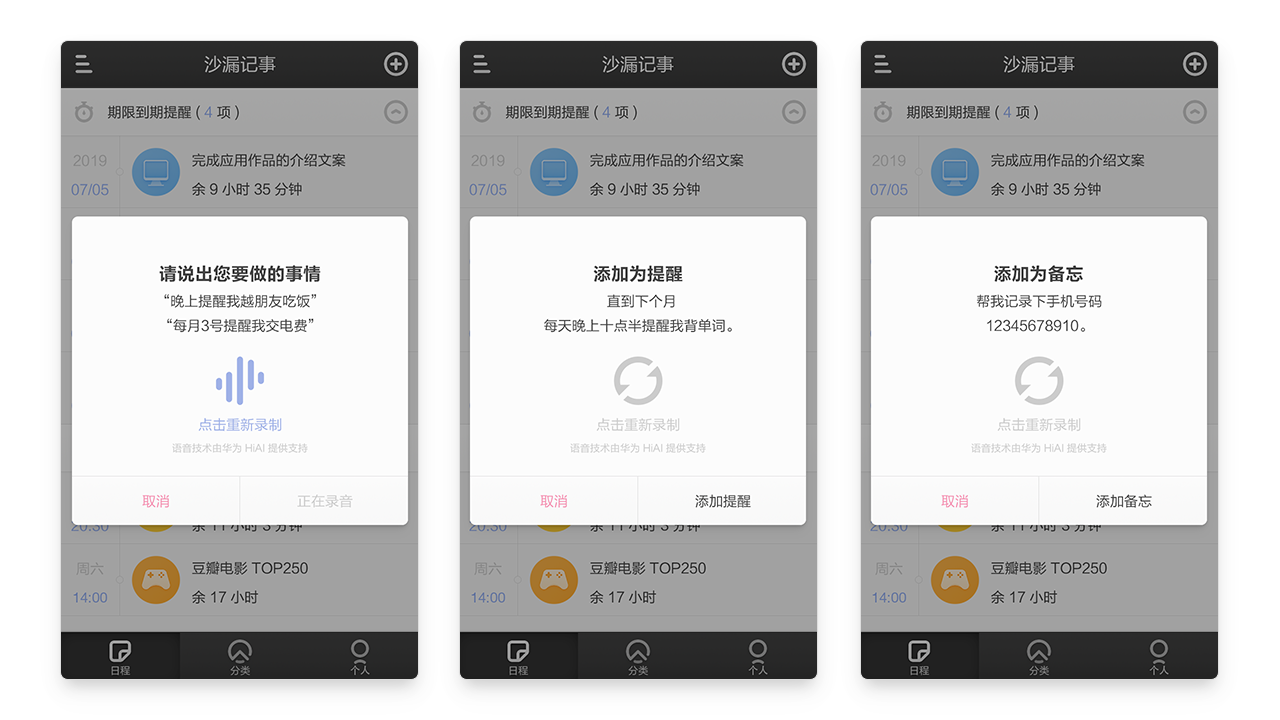
2 合作经验
3 AI模块嵌入
3.1 AI功能模块总体说明
为了更好的说明应用的AI模块,下面先介绍模块的总体架构。
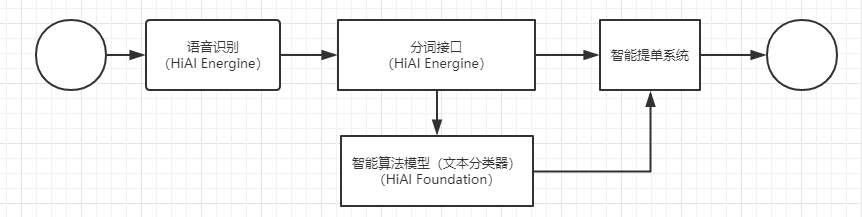
如上图所示,沙漏记事的AI功能模块主要由语音识别、分词接口、智能算法模型、智能提单系统四个部分组成,涉及了语音输入、文本分类、文本关键信息提取这三方面的内容。
虽然涉及的技术较多,但是在应用的实际操作中,需要用户参与的部分并不多。用户只需通过应用提供的语音输入入口说出自己想要记录的内容,在华为HIAI的帮助下,应用程序准确地将语音转换成文本,提取并计算出其中的时间、记事类型、提醒方式等关键信息,高效地完成一次记事。
具体的,可以从以下场景进行体会。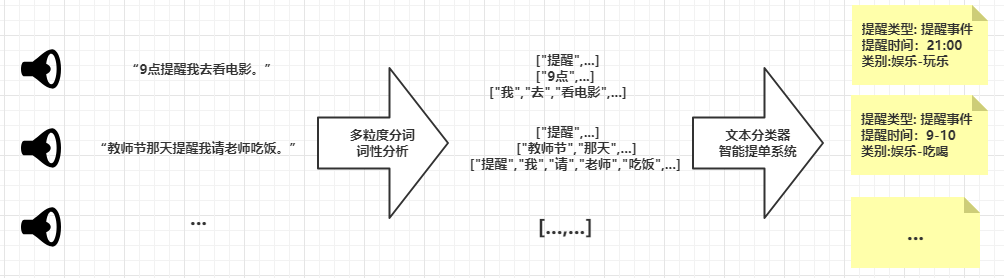
[例]通过语音输入”每天下午6点提醒我去操场跑步”。“语音识别”将识别语音内容并将其转换成文本,“分词接口”对文本进行多粒度的分词,同时标记出各个词语的词性,“词性组合过滤器”按照一定的词性组合规则对临近的分词结果进行重组。最后,通过分词和词性重组的结果,“文本分类器”计算并得出最大概率的类别,“智能提单系统”推算出提醒的时间以及提醒类型,完成记事事件的填写。
更进一步,整个大模块的整体架构如下图所示: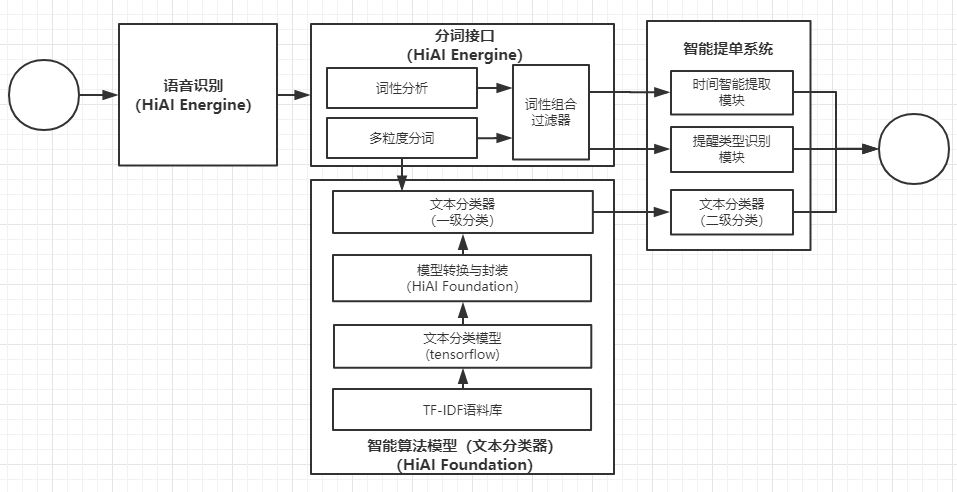
下面是沙漏记事中的AI功能模块的技术细节。
语音识别
语音识别模块使用了 HiAI Energine 的语音识别接口。常见的语音识别功能都需要网络的支持,凭借华为NPU,我们的语音识别模块在没有网络的情景下都能做到准确的语音识别。分词接口
分词接口部分使用了HiAIEnergine 的分词和词性标注的接口。多粒度分词,可以按不同的粒度提取出文本中的关键信息。词性标注,可以准确的判断出某个词是名词、动词、形容词等等,使得语义分析更方便扩展。
为了更好地将这一接口的功能运用到应用中去,我在接口原有的多粒度分词与词性标注的基础上做了更深一步的变化,增加了一个词性组合过滤器,目的是筛选出文本中不同词性组合的短语,为智能提单系统多种关键信息的提取做铺垫。智能算法模型(文本分类器)
HiAI Foundation DDK,是海思发布的人工智能计算SDK,该SDK面向人工智能应用程序开发人员和机器学习算法人员,通过使用HiAI DDK,可以将自己训练的caffe或Tensorflow模型运行在带有NPU的设备上,可以更好的提升移动端机器学习模型运行速度。
智能算法模型部分,即应用中的文本分类器,使用了HiAI Foundation DDK,将我们自己训练的tensorflow神经网络模型(文本分类器)集成到应用中去。
在模型训练与转换部分,我首先利用数据集构建了一个TF-IDF语料库,TF-IDF语料库在模型训练阶段和后面预测分类阶段都要用到,主要作用是将单条文本的分词结果转换成对应的TF-IDF词向量。然后,参照HiAI DDK上的算子表搭建并训练了tensorflow神经网络,使用的是多层感知机。模型训练完成后,利用HiAI DDK提供的工具对模型进行转换并封装成arr包供主程序调用。
文本分类器的使用过程为,接收分词接口分类出来的分词结果,使用TF-IDF语料库将分词结果转换成向量。然后,使用之前封装好的模型即可对向量的类别进行预测。
